OpenAI “o1-preview” моделын талаарх миний өнцөг
Өнгөрсөн шөнө (9 цагийн өмнө) OpenAI компани хамгийн сүүлд гаргасан o1 моделын preview буюу туршилтын хувилбар моделоо танилцуулжээ.
Энэ моделийн онцлог нь хариулахаасаа өмнө боддог (reasoning) гэнэ. Ингэснээр өмнөх моделиудаа бодвол илүү оновчтой, алдаа багатай хариулт өгч чаддаг болсон юм байна.
Чадамжууд
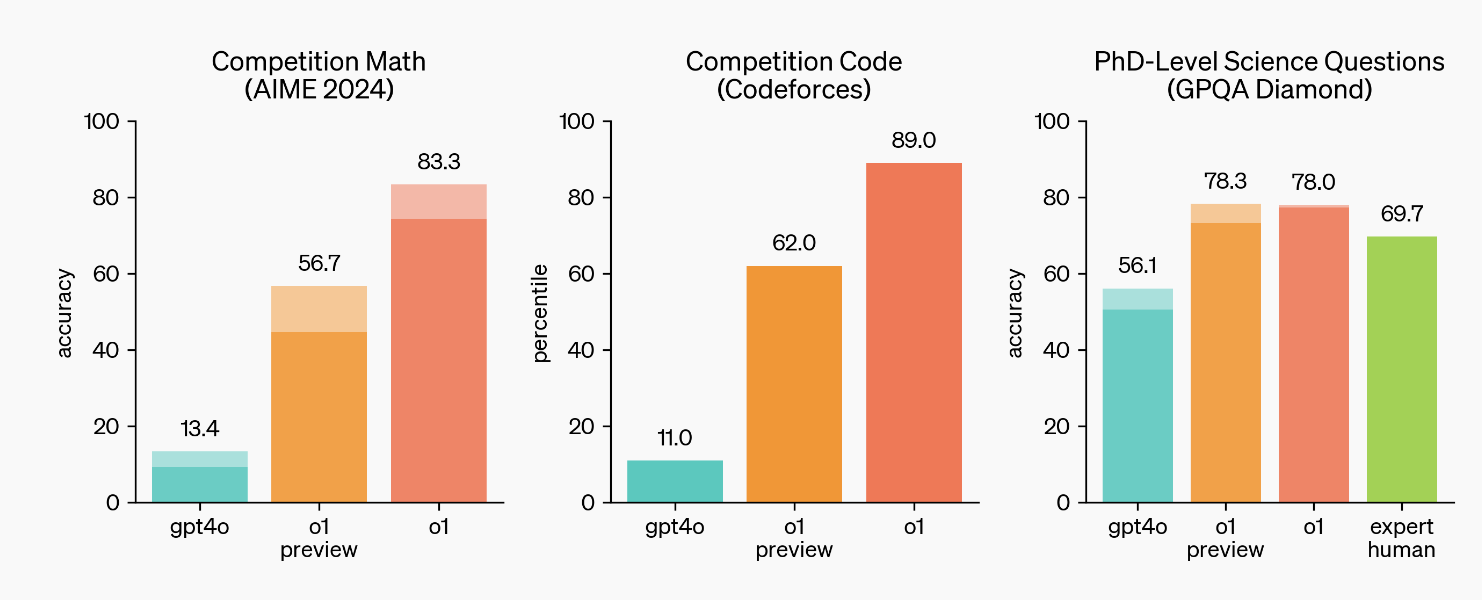
- Физик, Хими, Биологи зэрэг шинжлэх ухааны салбарын даалгавруудыг PhD түвшний хэмжээнд хариулж чаддаг болсон
- Олон улсын математикийн олимпиадын (International Mathematics Olympiad) бодлогуудыг 83% -тай бодож чаддаг болсон гэнэ(өмнөх хувилбар gpt-4o зөвхөн 13% -тай бодож чаддаг байсан)
-
Код бодолтын платформ дээрх бодлогуудыг 89%-тай бодож чаддаг болсон (gpt-4o 11% -тай бодож чаддаг)
- Өмнөх моделын чаддаггүй байсан хүнд логик шаардсан (puzzle) даалгавруудыг бодож чаддаг болсон байна:
- Код бичих чадвар нь өмнөхөөсөө хамгийн илүү болсон
Хэрхэн ажилладаг вэ ?
Энэ моделын гол онцлог нь хариулахаасаа өмнө бодохдоо (reasoning) илүү цагийг зарцуулдаг болсон. Энэ нь яаж ажилладаг вэ гэвэл:
- Өгөгдсөн оролтыг (prompt) -с эхлээд бодохдоо зориулж өөртөө урт хэмжээний үргэлжилсэн бодлын хэлхээг гаргана (a long internal chain of thought). Эдгээр нь reasoning tokens -ууд гэж нэрлэгдэнэ
- Оролтыг ойлгохын тулд нарийвчилж задлаад олон төрлийн боломжит хариултуудыг гаргаж авна.
- Reasoning tokens-уудыг гаргаж авсны дараа хэрэглэгч рүү өгөх үндсэн хариуг гаргаж өгнө (visible completion token). Ингэхдээ дотооддоо ашигласан reasoning token -г орхидог байна.
- reasoning token нь хэрэглэгчид харагдахгүй ч гэсэн хариулт гаргахад (context window) ашиглагдаж байгаа учраас төлбөр дээр гаралтын токеноор (output token) бодогдоно
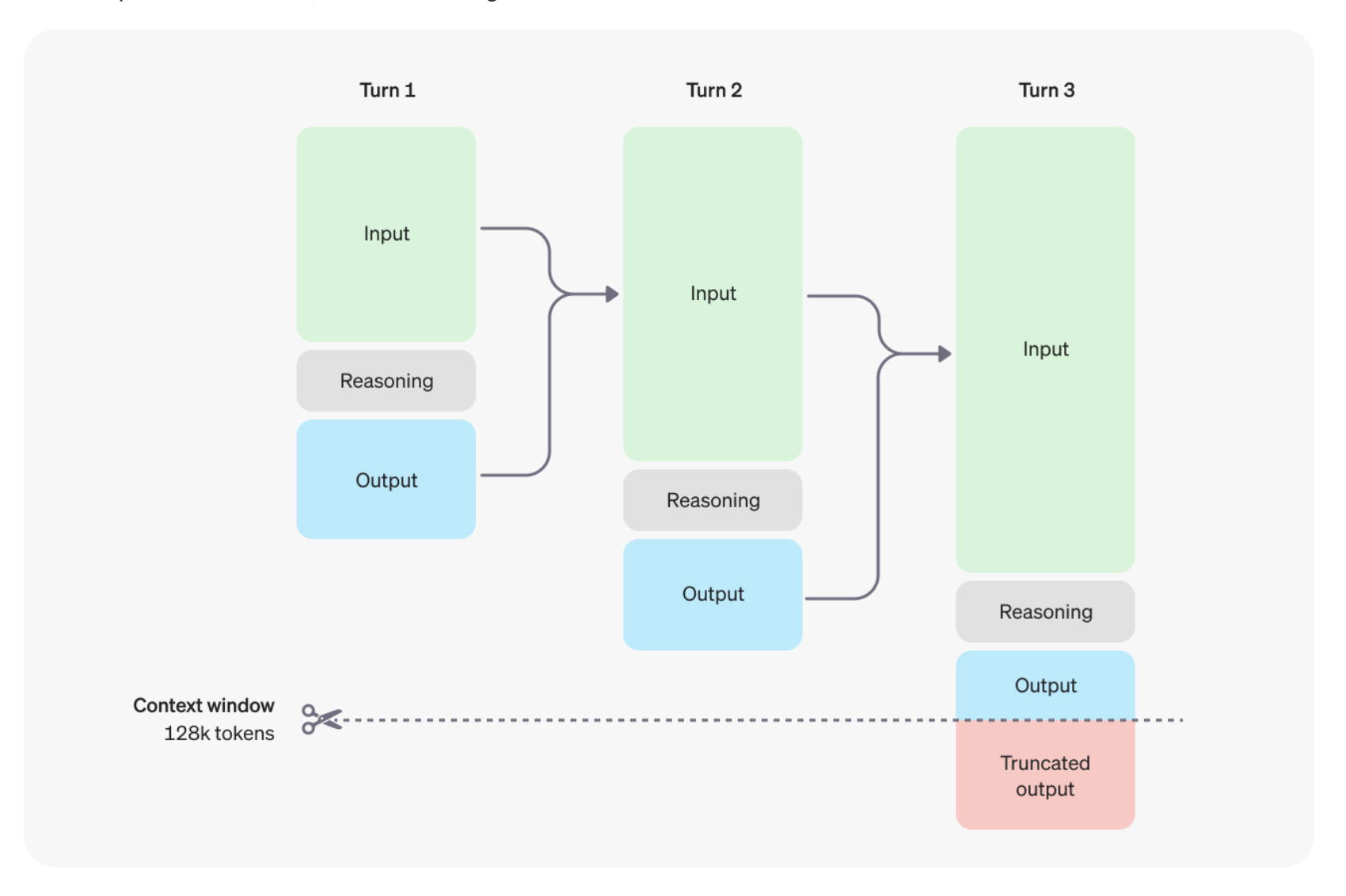
Бодох алхамуудыг дараах зурагт харууллаа
Дэлгэрэнгүй: https://platform.openai.com/docs/guides/reasoning
Тархины хэмжээ (context window)
o1-preview болон o1-mini моделууд 128,000 токены (1 токен гэдгийг ойролцоогоор 1 үг гэж ойлгож болно) багтаамжтай. Гаралтын токены урт (харагддаггүй бодолтын токен болон харагддаг гаралтын токен) мөн дараах дээд хязгаартай:
- o1-preview: 32,768 токен хүртэл
- o1-mini: 65,536 токен хүртэл
Асуудлын хэр хүндээс хамаарч модел нь дотооддоо ашигладаг бодолтын токеныг (reasoning token) хэдэн зуугаас хэдэн арван мянгаар нь ашиглаж болно гэж тайрласан байна.
Ашиглах боломжууд болон хязгаарлалтууд
Одоогоор зөвхөн ChatGPT Plus and Team эрхтэй хэрэглэгчид долоо хоногийн 30 асуулт (o1-mini моделийн хувьд 50 асуулт) асуух эрхтэй юм байна. Харин хөгжүүлэгч нарын хувьд зөвхөн tier 5 түвшний хэрэглэгчид минутанд 20 хүсэлт явуулах хязгаартайгаар ашиглаж болох юм байна.
Асуулт (prompt) хэрхэн асуувал зүгээр вэ
Өмнөх моделиудын хувьд think step by step зэрэг түлхүүр үгүүдийг ашиглавал илүү хариулт гаргаж өгдөг байсан бол o1, o1-mini хувьд өөрөө задалж боддог учраас асуултаа (prompt) энгийнээр шууд асуувал тохиромжтой гэнэ. Асуултуудыг дараах байдлаар асуувал илүү тохиромжтой гэнэ
- Энгийн бөгөөд шууд: модел нь илүү сайн ойлгодог болсон учир нарийвчилсан, дэлгэрэнгүй заавар оруулах шаардлагагүй болсон
- Chain-of-thought prompt шаардлагагүй: модел нь дотооддоо боддог учраас “think step by step” эсвэл “explain your reasoning” гэх зэрэг түлхүүр үгүүдийг ашиглах шаардлагагүй
- Тусгаарлах тэмдэгтүүдийг ашиглаж ялгаж өгөх: оролтын хэсгүүдийг тусд нь ялгахын тулд хашилт (”), XML tag зэрэг ялгах тэмдэгтүүдийг ашиглавал сайн
- Retrieval-Augmented Generation (RAG) -г хязгаарлагдмал түвшинд ашиглах: Модел хариулт боловсруулахдаа хэт төвөгтэй болгохоос сэргүүлж зөвхөн шаардлагатай мэдээллээр л хангаж өгөх хэрэгтэй
Бодлын хэлхээг нуух (Hiding the Chains of Thought)
Нуугдмал бодох процесс (hidden chain of thought) нь AI моделиудыг хянахад илүү боломжтой болгоно гэж дүгнэсэн байна. Өөрөөр хэлбэл энэ аргаар AI моделын бодлыг унших боломжтой гэсэн үг (read the mind of the model). Ингэснээр зохимжгүй хариултуудыг хэрэглэгчид рүү хүргэхгүй байх, мөн хууль дүрмүүдийг модельд зааж зүгшрүүлэх боломжтой болох юм байна. Одоогийн
Өрсөлдөөний давуу тал болон хэрэглэгчийн туршлага зэрэг олон хүчин зүйлээс хамаараад o1 шинэ моделын бодох алхамуудыг (дотоодын түүхий бодлын хэлхээг) хэрэглэгчид харуулахгүй байхаар шийдсэн гэнэ.
Юунд илүү тохиромжтой вэ
Дээр дурьдсанчлан шинжлэх ухааны илүү төвөгтэй бодлого, даалгавар зэрэгт ашиглахад илүү тохиромжтой бололтой. Хэдийгээр o1 модел нь анализ хийх чадвар өмнөх gpt-4o загвараас илүү хэдий ч бүх зүйл дээр илүү гэсэн үг биш гэж дурьдсан байна. Жишээ нь зураг оруулж асуух, функц дуудах (function calling) мөн хурдтай хариулт гаргаж чадваруудаараа gpt-4o модел одоогоор илүү дээр сонголт болно гэжээ
Дүгнэлт
Энэхүү OpenAI o1 модел гаргаснаар (AI модел нарийн төвөгтэй бодлого даалгавруудыг төвөггүй гүйцэтгэдэг болж байгаа нь) эксперт хүний хийж чадах түвшинд хүрснийг харуулж байх шиг санагдлаа. Цаашид хүний бүтээмж 10x дахин нэмэгдэхээр барахгүй шинжлэх ухааны салбаруудад олон арван шинэ нээлт хийгдэх болов уу